【課題】高エネルギー実験で生成された荷電粒子の飛跡を見つける#
この課題では、変分量子固有値ソルバー法を物理実験に応用することを考えてみます。特に高エネルギー物理の実験に着目し、その必須技術である「荷電粒子飛跡の再構成」を変分量子固有値ソルバー法を使って実現することを目指します。
はじめに#
変分量子固有値ソルバー法(Variational Quantum Eigensolver, VQE)を紹介したノートブックで、VQEの考え方と変分量子回路の基本的な実装の方法を学びました。ここでは、VQEの高エネルギー物理への応用を考えてみます。
高エネルギー実験では、高いエネルギーに加速した粒子(例えば陽子)を人工的に衝突させ、生成された多数の二次粒子を検出器で測定することで、その生成過程をつかさどる基礎物理反応を理解していきます。そのためには、検出器で測定された信号から生成粒子を同定し、そのエネルギーや運動量を正しく再構成することがとても重要です。この実習では、生成した物理反応を再構成するための最初のステップとして、「荷電粒子飛跡の再構成」をVQEで実現する方法について学んでいきます。
高エネルギー実験#
LHC実験の概要#

LHC(大型ハドロン加速器 Large Hadron Collider)は、スイスとフランスの国境に位置する欧州原子核研究機構(CERN)で運転されている円形の加速器です。地下約100 mに掘られた周長27 kmのトンネルの中に置かれ、6.8 TeVのエネルギーまで陽子を加速することができます(1 TeV = \(10^{12}\) eV = \(1.602 \times 10^{-7}\) J)。その加速された陽子を正面衝突させることで、世界最高エネルギーである13.6 TeV での陽子衝突実験を実現しています(左上の写真)。右上の写真は、地下トンネルに設置されたLHCの写真です。
LHCでは4つの実験(ATLAS, CMS, ALICE, LHCb)が進行中ですが、その中でもATLASとCMSは大型の汎用検出器を備えた実験です(左下の写真が実際のATLAS検出器)。陽子衝突で発生した二次粒子を周囲に設置した高精度の検出器で観測することで、さまざまな素粒子反応の観測や新しい現象の探索などを行っています。右下の絵はATLAS検出器で実際に記録した粒子生成反応の一つで、これは2012年にATLASとCMSで発見されたヒッグス粒子の候補を示したものです(ヒッグス粒子は単体で測定されるわけではなく、その崩壊の結果出てきた多数の粒子を観測するのでこのように見えます)。
荷電粒子の測定#
ATLASやCMS実験の検出器は、異なる性質を持った検出器を内側から外側に階層的に配置しています。最内層の検出器は荷電粒子の再構成や識別に使われる検出器で、実験では最も重要な検出器の一つです。この検出器はそれ自体が約10層程度の層構造を持っており、一つの荷電粒子が通過したとき、複数の検出器信号を作ります。 例えば、左下図にあるように一度の陽子衝突で無数の粒子が生成され、それらが検出器に「ヒット」と呼ばれる信号を作ります(図中の白、黄色、オレンジ等の点に相当)。このヒットの集合から「ある荷電粒子が作ったヒットの組み合わせ」を選び、その粒子の「飛跡」を再構成します。右下図のいろいろな色の曲線が飛跡に対応します。この飛跡の再構成(トラッキングと呼ぶ)は、ATLASやCMS実験に限らず、高エネルギー実験では最も重要な実験技術の一つと言えます。
飛跡の再構成は本質的にはいわゆる「組合せ最適化」問題であるため、問題のスケール(粒子数)について計算量が指数関数的に増えます。LHCでビーム強度(一度に加速する粒子の数)を上げたり、将来さらに高いエネルギーの衝突型加速器実験を行ったりする場合、現在の(古典)計算機では飛跡を完全に再構成することが困難になることが予想されています。そこで、量子コンピュータを利用して計算時間を短縮するなど、様々なアプローチが検討・研究されています。
TrackMLチャレンジ#
CERNでは、将来の加速器計画として「高輝度LHC」(2027年に開始予定)と呼ばれるLHCの増強計画を進めており、実際にLHCのビーム強度が大幅に増加することになっています。高輝度LHC では、陽子の衝突頻度が現在の10倍近くに上がることになっており、発生する2次粒子の数もそれに応じて増えるため、トラッキングの効率化は実は喫緊の課題です。
2027年から量子コンピュータを実際の実験で利用する見通しは残念ながらありませんが、古典コンピュータでも最先端の機械学習手法の導入などでまだまだアルゴリズムを改良する余地があると考えた研究者らによって、2018年にTrackML Particle Trackingチャレンジというコンペティションが開催されました。このコンペティションでは、高輝度LHCでの実験環境のシミュレーションから得られた検出器のヒット情報が公開データとして参加者(物理学者に限らず誰でも参加可能)に提供され、参加者は自身のアルゴリズムをこのデータに対して適用して、トラッキングの早さや精度を競い合いました。
問題:VQEによるトラッキング#
この課題では、上のTrackMLチャレンジの公開データを用いて、VQEを数理最適化アルゴリズムとして応用してトラッキングを行うことを目指します。ただし、現在の量子コンピュータでは大きなサイズの問題を解くことはまだ難しいため、サイズの小さい問題、つまり少数の生成粒子が生成された場合に絞って検討を行います。
まず、必要なライブラリを最初にインポートします。
import os
import sys
import logging
import pprint
import numpy as np
import h5py
import matplotlib.pyplot as plt
from qiskit import QuantumCircuit
from qiskit.circuit.library import TwoLocal
from qiskit.primitives import BackendEstimator
from qiskit_algorithms.minimum_eigensolvers import VQE, NumPyMinimumEigensolver
from qiskit_algorithms.optimizers import SPSA, COBYLA
from qiskit_algorithms.gradients import ParamShiftEstimatorGradient
from qiskit.quantum_info import SparsePauliOp, Statevector
from qiskit_optimization.applications import OptimizationApplication
from qiskit_aer import AerSimulator
ハミルトニアンの構成とVQEの実行#
VQEを一般の最適化アルゴリズムとして利用するには、問題を何らかのハミルトニアンとして表現する必要があります。問題の最適解がそのハミルトニアンの基底(最低エネルギー)状態に対応するように構成できれば、VQEがその最適解を近似してくれます。
前準備#
この課題ではTrackMLチャレンジのデータを用いますが、元のデータは扱いが難しいため、量子計算に用いやすいように前処理を行なったデータを使います。ここでのデータの準備やこの後のハミルトニアンの構成は、[BBC+19]に基づいています。
まず下図に示したように、検出器3層に渡って連続するヒットを選び出します(点線で囲まれた3層ヒットのことを、ここでは「セグメント」と呼ぶことにします)。色のついた点がヒットだと考えてください。これらのセグメントはただヒットを結んだだけなので、全て実際の粒子の飛跡に対応しているとは限りません。別々の粒子によるヒットを結びつけてしまっている場合もあれば、検出器の電気的ノイズをヒットとして記録してしまい、そこからセグメントを作ってしまっていることもあり得ます。ただし、そのような「フェイク」のセグメントはあらゆる方向を向き得るのに対し、実際に陽子衝突で生じた粒子由来のセグメントは検出器中心を向きます。そこで、各セグメントについてどれだけ検出器中心の方を向いているかに基づいてスコアをつけます。このスコアは後で説明する理由によって、セグメントが検出器中心を向いているほど値が小さくなるように設定します。また、明らかにフェイクなセグメントは最初から無視するので、以降はスコアが一定以下のもののみを考えます。
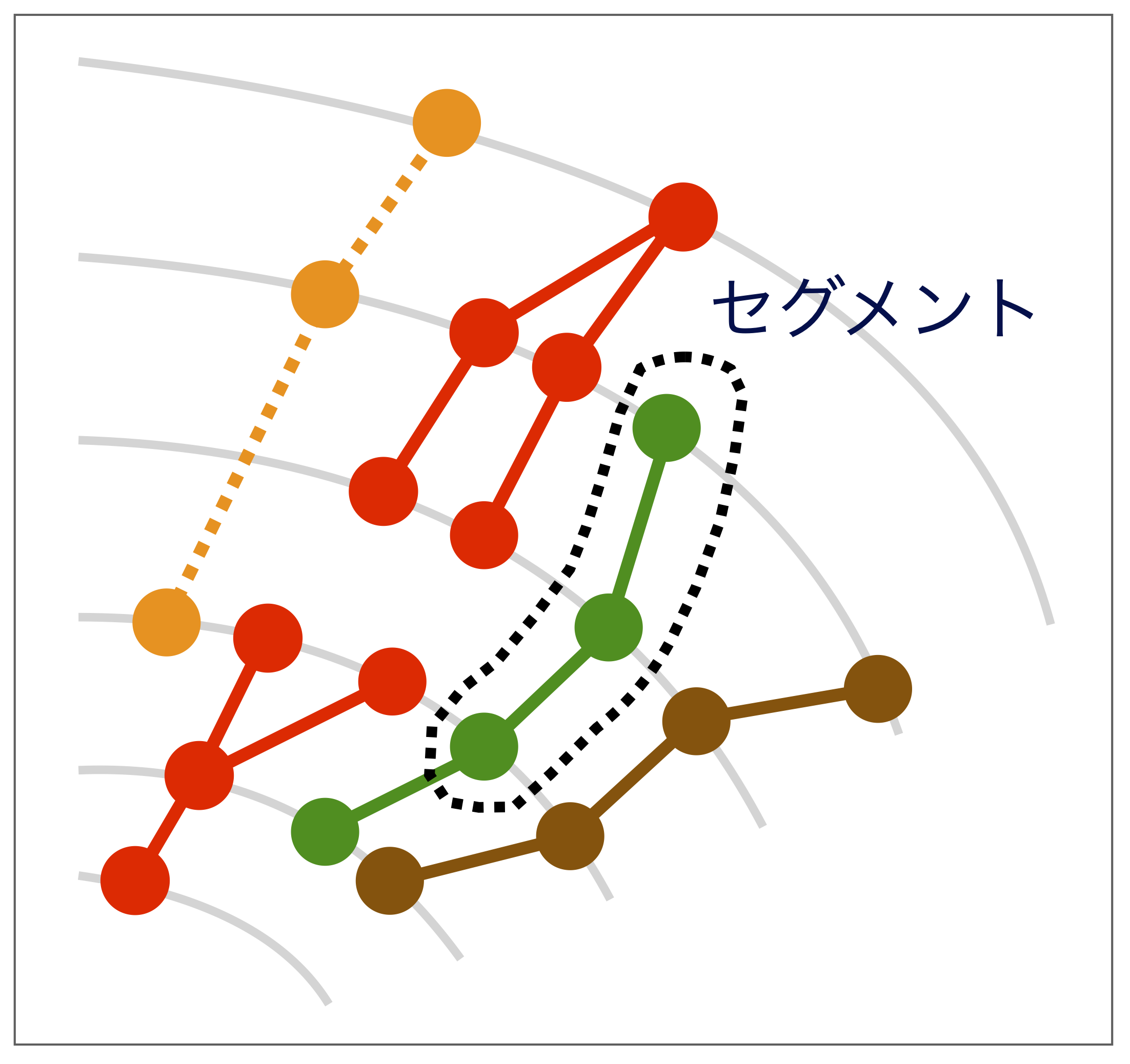
次に、選び出されたセグメントから総当りでペアを作り、それぞれのペアについて、二つのセグメントが同一の荷電粒子が作る飛跡とどれぐらい無矛盾なのかを表すスコアをつけます。 このスコアは、セグメントのペアが同一飛跡に近くなるにつれ、値が-1に近づくように設定されています。
例えば、セグメントを構成する3つのヒットのうちの1つが2つのセグメントに共有されているケース(図中で赤で示した場合に相当)は、飛跡の候補としては適切でないのでスコアが+1になります。なぜかと言うと、赤で示したような「枝分かれ」あるいは「収束」したような飛跡というのは、今興味がある飛跡(検出器中心で発生した荷電粒子の軌道)とは矛盾しているからです。
また、図中のオレンジのようなケース(途中でヒットが抜けているようなセグメント)や茶色のケース(飛跡がジグザグしているもの)も興味のある飛跡とは言えないため、スコアは-1より大きな値に設定されます。なぜジグザグした飛跡が好ましくないかですが、一様な磁場に直交する方向に荷電粒子が入射した場合、その入射平面ではローレンツ力のせいで一定の曲率で同じ方向に粒子の軌道が曲がるからです。
最初に下のセルを実行し、すでに作成してあるデータを取得します。データに含まれるセグメント(triplet)の数などの情報をプリントアウトするようにしています。
from hepqpr.qallse import *
density = 0.0015
prefix = 'ds'+str(density)
# ==== BUILD CONFIG
loglevel = logging.INFO
input_path = 'source/data/ds/'+prefix+'/event000001000-hits.csv'
output_path = 'source/data/ds/'+prefix+'/'
model_class = QallseD0 # model class to use
extra_config = dict() # model config
dump_config = dict(
output_path = 'source/data/ds/'+prefix+'/',
prefix=prefix+'_',
xplets_kwargs=dict(format='json', indent=3), # use json (vs "pickle") and indent the output
qubo_kwargs=dict(w_marker=None, c_marker=None) # save the real coefficients VS generic placeholders
)
# ==== configure logging
logging.basicConfig(
stream=sys.stderr,
format="%(asctime)s.%(msecs)03d [%(name)-15s %(levelname)-5s] %(message)s",
datefmt='%Y-%m-%dT%H:%M:%S')
logging.getLogger('hepqpr').setLevel(loglevel)
# ==== build model
# load data
dw = DataWrapper.from_path(input_path)
doublets = pd.read_csv(input_path.replace('-hits.csv', '-doublets.csv'))
# build model
model = model_class(dw, **extra_config)
model.build_model(doublets)
# dump model to a file
dumper.dump_model(model, **dump_config)
QUBO#
以上のセットアップで、各セグメントを粒子飛跡の一部として採用するかフェイクとして棄却するかを考えます。具体的には、\(N\)個のセグメントのうち\(i\)番目の採用・棄却を二値変数\(T_i\)の値1と0に対応させ、目的関数
を最小化する\(\{T_i\}\)を求めます。ここで\(a_i\)は上で決めたセグメント\(i\)のスコア、\(b_{ij}\)はセグメント\(i\)と\(j\)のペアのスコアです。\(a_i\)の値が小さい(検出器中心を向いている)、かつ\(b_{ij}\)の値が小さい(正しい飛跡と無矛盾な)ペアを組んでいるセグメントを採用し、そうでないものを棄却するほど、\(O\)の値は小さくなります。採用すべきセグメントが決まれば、それに基づいてすべての粒子飛跡を再構成できるので、この最小化問題を解くことがトラッキングに対応します。
上のような形式の最適化問題をQUBO(Quadratic Unconstrained Binary Optimization、2次制約無し2値最適化)と呼びます。一見特殊な形式ですが、実は様々な最適化問題(例えば有名な巡回セールスマン問題なども)がQUBOの形に落とし込めることが知られています。また、ここでは直接関係しませんが、量子アニーリングマシンと呼ばれるタイプの量子コンピュータでは、QUBOを解くことが動作の基本です。
まず、上のセルで作ったデータからQUBOを作成します
import pickle
from os.path import join as path_join
from hepqpr.qallse.other.stdout_redirect import capture_stdout
from hepqpr.qallse.other.dw_timing_recorder import solver_with_timing, TimingRecord
from hepqpr.qallse.plotting import *
# ==== RUN CONFIG
nreads = 10
nseed = 1000000
loglevel = logging.INFO
input_path = 'source/data/ds/'+prefix+'/event000001000-hits.csv'
qubo_path = 'source/data/ds/'+prefix+'/'
# ==== configure logging
logging.basicConfig(
stream=sys.stdout,
format="%(asctime)s.%(msecs)03d [%(name)-15s %(levelname)-5s] %(message)s",
datefmt='%Y-%m-%dT%H:%M:%S')
logging.getLogger('hepqpr').setLevel(loglevel)
# ==== build model
# load data
dw = DataWrapper.from_path(input_path)
pickle_file = prefix+'_qubo.pickle'
with open(path_join(qubo_path, pickle_file), 'rb') as f:
Q = pickle.load(f)
#print(Q)
作ったQUBOから、スコア\(a_{i}\)と\(b_{ij}\)を読み出します。
# スコアの読み込み
n_max = 100
nvar = 0
key_i = []
a_score = np.zeros(n_max)
for (k1, k2), v in Q.items():
if k1 == k2:
a_score[nvar] = v
key_i.append(k1)
nvar += 1
a_score = a_score[:nvar]
b_score = np.zeros((n_max,n_max))
for (k1, k2), v in Q.items():
if k1 != k2:
for i in range(nvar):
for j in range(nvar):
if k1 == key_i[i] and k2 == key_i[j]:
if i < j:
b_score[j][i] = v
else:
b_score[i][j] = v
b_score = b_score[:nvar,:nvar]
print(f'Number of segments: {a_score.shape[0]}')
# 最初の5x5をプリント
print(a_score[:5])
print(b_score[:5, :5])
Ising形式#
QUBOの目的関数はまだハミルトニアンの形になっていない(エルミート演算子でない)ので、VQEを使ってこの問題を解くにはさらに問題を変形する必要があります。ここで\(T_i\)が\(\{0, 1\}\)のバイナリー値を持つことに着目すると、
で値\(\{+1, -1\}\)を持つ変数\(s_i\)を定義できます。次に、\(\{+1, -1\}\)はパウリ演算子の固有値でもあるため、\(s_i\)を量子ビット\(i\)にかかるパウリ\(Z\)演算子で置き換えると、\(N\)量子ビット系の各計算基底がセグメントの採用・棄却をエンコードする固有状態となるような目的ハミルトニアン
が得られます。これは物理を始め自然科学の様々な場面で登場するIsing模型のハミルトニアンと同じ形になっています。右辺の\(\text{constant}\)はハミルトニアンの定数項で、変分法において意味を持たないので以降は無視します。
以下のセルで、上の処方に従ってIsingハミルトニアンの係数\(h_i\)と\(J_{ij}\)を計算してください。
num_qubits = a_score.shape[0]
coeff_h = np.zeros(num_qubits)
coeff_J = np.zeros((num_qubits, num_qubits))
##################
### EDIT BELOW ###
##################
# coeff_hとcoeff_Jをb_ijから計算してください
##################
### EDIT ABOVE ###
##################
次に、この係数をもとに、VQEに渡すハミルトニアンをSparsePauliOpとして定義します。VQEの実装ではSparsePauliOpは単一のパウリ積\(ZXY\)を表現するのに使いましたが、実はパウリ積の和も同じクラスを使って表現できます。例えば
は
H = SparsePauliOp(['IIZ', 'ZZI', 'ZIZ'], coeffs=[0.2, 0.3, 0.1])
となります。このとき、通常のQiskitの約束に従って、量子ビットの順番が右から左(一番右が第0量子ビットにかかる演算子)であることに注意してください。
##################
### EDIT BELOW ###
##################
# 係数が0でないパウリ積をすべて拾い出し、対応する係数の配列を作成してください
pauli_products = []
coeffs = []
##################
### EDIT ABOVE ###
##################
hamiltonian = SparsePauliOp(pauli_products, coeffs=coeffs)
VQEの実行#
上で定義したハミルトニアンを元に、VQEを使ってエネルギーの最小固有値(の近似解)を求めていきます。ただその前に、このハミルトニアンの行列を対角化して、エネルギーの最小固有値とその固有ベクトルを厳密に計算した場合の答えを出してみましょう。
# ハミルトニアン行列を対角化して、エネルギーの最小固有値と固有ベクトルを求める
ee = NumPyMinimumEigensolver()
result_diag = ee.compute_minimum_eigenvalue(hamiltonian)
# 最小エネルギーに対応する量子ビットの組み合わせを表示
print(f'Minimum eigenvalue (diagonalization): {result_diag.eigenvalue.real}')
# 解状態を計算基底で展開し、最も確率の高い計算基底を選ぶ
optimal_segments_diag = OptimizationApplication.sample_most_likely(result_diag.eigenstate)
print(f'Optimal segments (diagonalization): {optimal_segments_diag}')
次に、VQEで最小エネルギーを求めてみます。オプティマイザーとしてSPSAあるいはCOBYLAを使う場合のコードは以下のようになります。
backend = AerSimulator()
# Estimatorインスタンスを作る
estimator = BackendEstimator(backend)
# VQE用の変分フォームを定義。ここではTwoLocalという組み込み関数を使う
ansatz = TwoLocal(num_qubits, 'ry', 'cz', 'linear', reps=1)
# オプティマイザーを選ぶ
optimizer_name = 'SPSA'
if optimizer_name == 'SPSA':
optimizer = SPSA(maxiter=300)
grad = ParamShiftEstimatorGradient(estimator)
elif optimizer_name == 'COBYLA':
optimizer = COBYLA(maxiter=500)
grad = None
# パラメータの初期値をランダムに設定
rng = np.random.default_rng()
init = rng.uniform(0., 2. * np.pi, size=len(ansatz.parameters))
# VQEオブジェクトを作り、基底状態を探索する
vqe = VQE(estimator, ansatz, optimizer, gradient=grad, initial_point=init)
result_vqe = vqe.compute_minimum_eigenvalue(hamiltonian)
# 最適解のパラメータ値をansatzに代入し、状態ベクトルを計算する
optimal_state = Statevector(ansatz.assign_parameters(result_vqe.optimal_parameters, inplace=False))
# 最小エネルギーに対応する量子ビットの組み合わせを表示
print(f'Minimum eigenvalue (VQE): {result_vqe.eigenvalue.real}')
optimal_segments_vqe = OptimizationApplication.sample_most_likely(optimal_state)
print(f'Optimal segments (VQE): {optimal_segments_vqe}')
おまけ#
Trackingがうまく行っても、この答えだと0と1が並んでいるだけで面白くないですよね。正しく飛跡が見つかったかどうか目で確認するため、以下のコードを走らせてみましょう。厳密対角化の結果を図示する時はtype = "diag"、VQEの結果を図示する時はtype = "vqe"としてください。
正しい計算ができていれば、いくつかの情報とともに”tracks found: 1”という結果が出て、その時の飛跡の図が作られます。 この図はQUBOを定義する時に使った検出器のヒット位置をビーム軸に垂直な平面に投影したものです。再構成が成功していれば、ヒットが繋がって飛跡として再構成されていることが見て取れるはずです。緑の線が実際に見つかった飛跡です。
from hepqpr.qallse import DataWrapper, Qallse, TrackRecreaterD
from hepqpr.qallse.plotting import iplot_results, iplot_results_tracks
from hepqpr.qallse.utils import diff_rows
# どちらの結果をプロットするか指定する
# diag = 厳密対角化の結果
# vqe = VQEの結果
type = "diag"
#type = "vqe"
if type == "diag":
optimal_segments = optimal_segments_diag
elif type == "vqe":
optimal_segments = optimal_segments_vqe
# ここで {ID: 0 or 1} の辞書を作っている
samples = dict(zip(key_i, optimal_segments))
# 結果を取得する
all_doublets = Qallse.process_sample(samples)
final_tracks, final_doublets = TrackRecreaterD().process_results(all_doublets)
input_path = 'source/data/ds/'+prefix+'/event000001000-hits.csv'
dw = DataWrapper.from_path(input_path)
p, r, ms = dw.compute_score(final_doublets)
trackml_score = dw.compute_trackml_score(final_tracks)
print(f'SCORE -- precision (%): {p * 100}, recall (%): {r * 100}, missing: {len(ms)}')
print(f' tracks found: {len(final_tracks)}, trackml score (%): {trackml_score * 100}')
dims = ['x', 'y']
_, missings, _ = diff_rows(final_doublets, dw.get_real_doublets())
dout = 'plot-ising_'+type+'_found_tracks.html'
iplot_results(dw, final_doublets, missings, dims=dims, filename=dout)
from IPython.display import HTML
HTML(dout)
提出するもの
ハミルトニアンを実装する部分のコード